enforcing constraints from relation R to relation S, the following violation are possible:
insert/update R introduces values not found in S
deletion/update to S causes tuple of R to “dangle”
ex: suppose R=Sell∩S=Beer
delete or update to S that removes a beer value found in some tuples of R
actions:
Default: reject modification
CASCADE: make the same changes in Sells
Delete beer: delete Sells tuple
Update beer: change value in Sells
SET NULL: change beer to NULL
Can choose either CASCADE or SET NULL as policy, otherwise reject as default
create table Sells ( bar CHAR(20), beer CHAR(20) CHECK (beer IN (SELECT name FROM Beers)), price REAL CHECK (price <= 5.00), FOREIGN KEY(beer) REFERENCES Beers(name) ON DELETE SET NULL ON UPDATE CASCADE)
attributed-based check
CHECK(<cond>): cond may use name of attribute, but any other relation/attribute name MUST BE IN subquery
CHECK only runs when a value for that attribute is inserted or updated.
Tuple-based checks
added as a relation-schema element
check on insert or update only
create table Sells ( bar CHAR(20), beer CHAR(20), price REAL, CHECK (bar = 'Joe''s Bar' OR price <= 5.00),)
queries
SELECT name FROM Beers WHERE manf = 'Anheuser-Busch';SELECT t.name FROM Beers t WHERE t.manf = 'Anheuser-Busch';SELECT * FROM Beers WHERE manf = 'Anheuser-Busch';SELECT name AS beer, manf FROM Beers WHERE manf = 'Anheuser-Busch';SELECT bar, beer, price*95 AS priceInYenFROM Sells;-- constants as expr (using Likes(drinker,beer))SELECT drinker, 'likes Bud' as whoLikesBudFROM LikesWHERE beer = 'Bud';
patterns
% is any string, and _ is any character
SELECT name FROM DrinkersWHERE phone LIKE '%555-_ _ _ _';
In sql, logics are 3-valued: TRUE, FALSE, UNKNOWN
comparing any value with NULL yields UNKNOWN
A tuple in a query answer iff the WHERE is TRUE
ANY(<queries>) and ALL(<queries>) ensures anyof or allof relations.
IN operator
IN is concise
SELECT * FROM Cartoons WHERE LastName IN ('Simpsons', 'Smurfs', 'Flintstones')
IN is a predicate about R tuples
-- (1,2) satisfies the condition, 1 is output onceSELECT a FROM R -- loop oncewhere b in (SELECT b FROM S);-- (1,2) with (2,5) and (1,2) with (2,6) both satisfies the condition, 1 is output twiceSELECT a FROM R, S -- double loopWHERE R.b = S.b;
NOT EQUAL operator in SQL is <>
Difference between ANY and NOT IN
ANY means not = a, or not = b, or not = c
NOT IN means not = a, and not = b, and not = c. (analogous to ALL)
EXISTS operator
EXISTS(<subquery>) is true iff subquery result is not empty.
UNION, INTERSECT, EXCEPT
structure: (<subquery>)<predicate>(<subquery>)
bag
or a multiset, is like a set, but an element may appear more than once.
Force results to be a set with SELECT DISTINCT
Force results to be a bag with UNION ALL
ORDER BY ops followed with desc
insert, update, delete
INSERT INTO Likes VALUES('Sally', 'Bud');-- orINSERT INTO Likes(beer, drinker) VALUES('Bud', 'Sally');
add DEFAULT value during CREATE TABLE (DEFAULT value will be used if inserted tuple has no value for given attributes)
create table Drinkers ( name CHAR(30) PRIMARY KEY, addr CHAR(50) DEFAULT '123 Sesame Street', phone CHAR(16));-- in this case, this will use DEFAULT value for addr-- | name | address | phone |-- | Sally | 123 Sesame Street | NULL |INSERT INTO Drinkers(name) VALUES('Sally');
Those drinkers who frequent at least one bar that Sally also frequents
INSERT INTO Buddies (SELECT d2.drinker FROM Frequents d1, Frequents d2 WHERE d1.drinker = 'Sally' AND d2.drinker <> 'Sally' AND d1.bar = d2.bar)
DELETE FROM:
-- remove a relationDELETE FROM Beers WHERE name = 'Bud';-- remove all relationDELETE FROM Likes;-- Delete from Beer(name, manf) all beers for which there is another beer by the same manufacturerDELETE FROM Beers b WHERE EXISTS ( SELECT name FROM Beers WHERE manf = b.manf AND name <> b.name )
SUM, AVG, COUNT, MIN, MAX can be applied toa column in SELECT clause
COUNT(*) counts the number of tuples
-- find average price of BudSELECT AVG(price) FROM Sells WHERE beer = 'Bud';-- to get distinct value, then use DISTINCESELECT COUNT(DISTINCT price) FROM Sells WHERE beer = 'Bud';
NULL never contributes to a sum, average, or count
however, if all values in a column are NULL, then aggregation is NULL
exception: COUNT of an empty set is 0
GROUP BY: according to the values of all those attributes, and any aggregation is applied only within each group:
-- find the youngest employees per ratingSELECT rating, MIN(age)FROM EmployeesGROUP BY rating-- find for each drinker the average price of Bud at the bars they frequentSELECT drinker, AVG(price)FROM Frequents, SellsWHERE beer = 'Bud' AND Frequents.bar = Sells.barGROUP BY drinker;
restriction on SELECT with aggregation
each element of SELECT must be either:
Aggregated
An attribute on GROUP BY list
illegal example
SELECT bar,beer,AVG(price) FROM Sells GROUP BY bar-- only one tuple out for each bar, no unique way to select which beer to output
HAVING(<condition>)may followed by GROUP_BY
If so, the condition applies to each group, and groups not satisfying the condition are eliminated.
-- Get average price of beer given all beer groups exists with at-- least three bars or manufactured by Pete'sSELECT beer, AVG(price)FROM SellsGROUP BY beerHAVING COUNT(bar) >= 3 OR beer in (SELECT name FROM Beers WHERE manf = 'Pete''s');
requirements on HAVING:
Anything goes in a subquery
Outside subqueries they may refer to attributes only if they are either:
A grouping attribute
aggregated
cross product (cartesian product)
-- Frequents x Sells-- (Bar) | Beer | Price | Drinker | (Bar)-- Joe | Bud | 3.00 | Aaron | Joe-- Joe | Bud | 3.00 | Mary | JaneSELECT drinkerFROM Frequents, SellsWHERE beer = 'Bud' AND Frequents.bar = Sells.bar;
Or known as join operations⇒ all join operations are considered cartesian products.
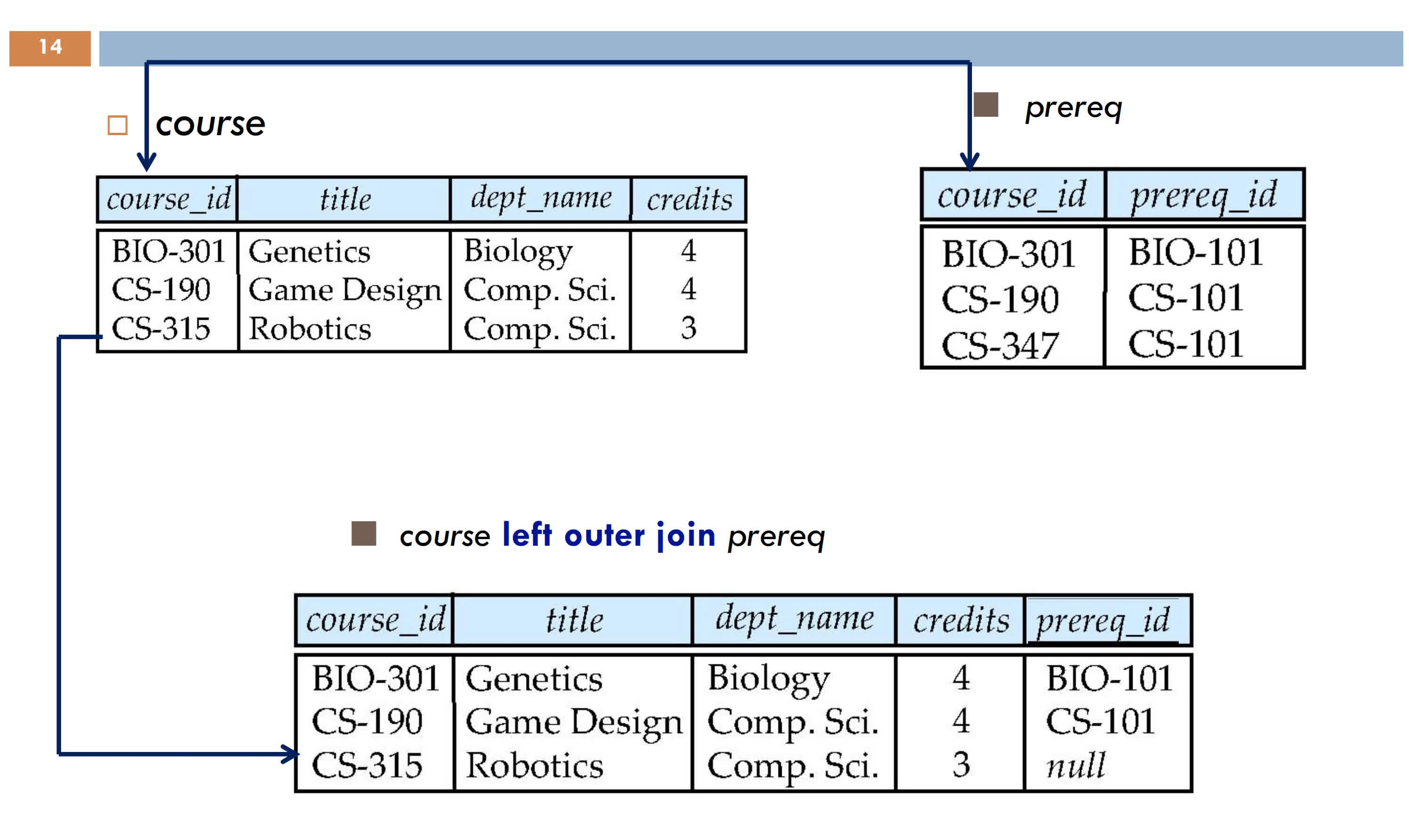
Outer join preserves dangling tuples by padding with NULL
A tuple of R that has no tuple of S which it joins is said to be dangling
Left outer join
Right outer join
full outer join
inner join
R [NATURAL] [LEFT|RIGHT|FULL] OUTERJOIN [ON<condition>] S-- exampleR NATURAL FULL OUTERJOIN S
natural: check equality on all common attributes && no two attributes with same name
left: padding dangling tuples of R only
right: padding dangling tuples of S only
full: padding both (default)
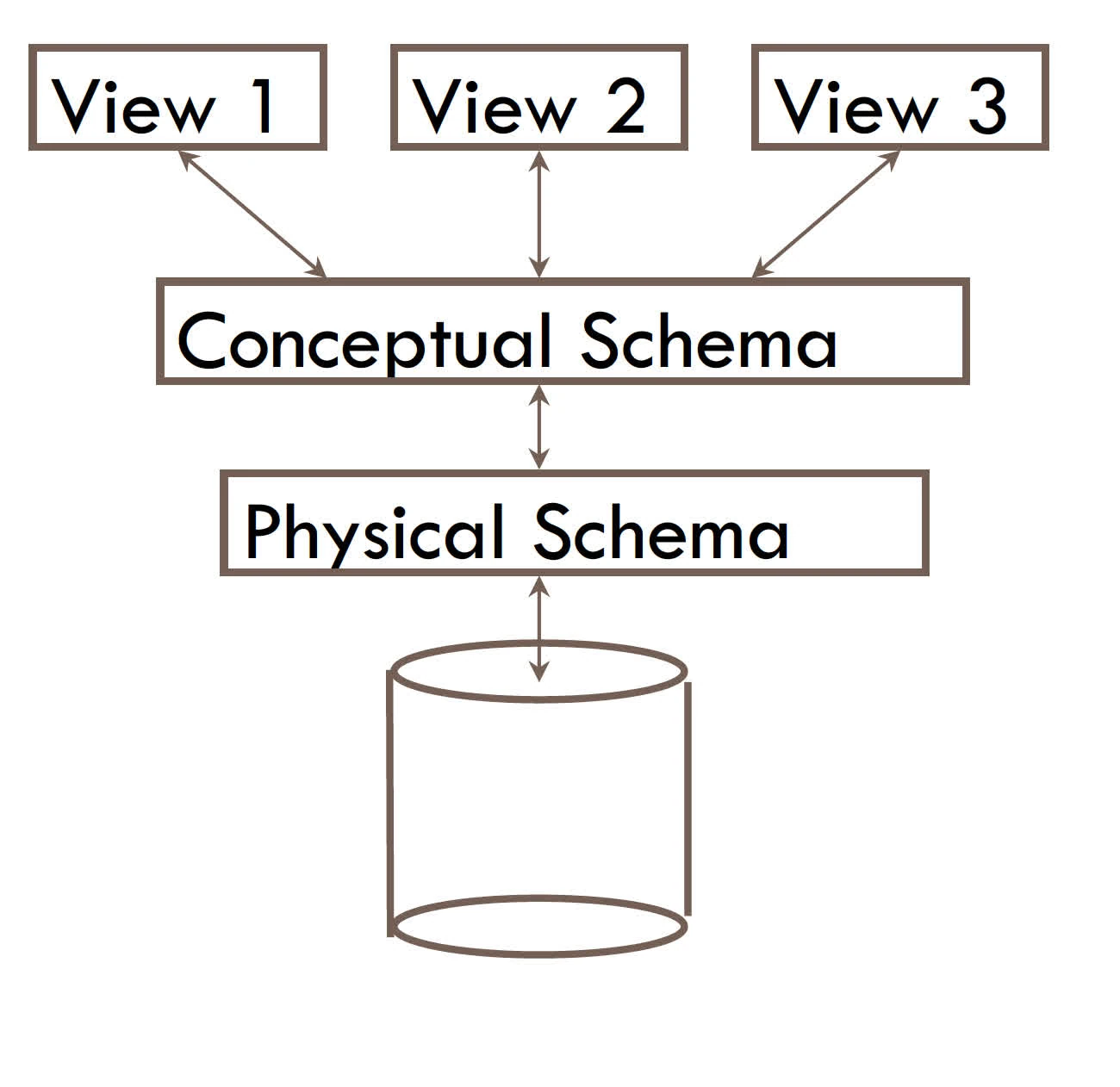
views
many views (how users see data), single logical schema (logical structure) and physical schema (files and indexes used)
virtual views does not stored in database (think of query for constructing relations)
materialized views are constructed and stored in DB.
view default to virtual
CREATE [MATERIALIZED] VIEW <name> as <query>;-- example: CanDrink(drinker, beer)create view CanDrink AS SELECT drinker, beer FROM Frequents f, Sells s WHERE f.bar = s.bar;
Usually one shouldn’t update view, as it simply doesn’t exists.
index
idea: think of DS to speed access tuple of relations, organize records via tree or hashing
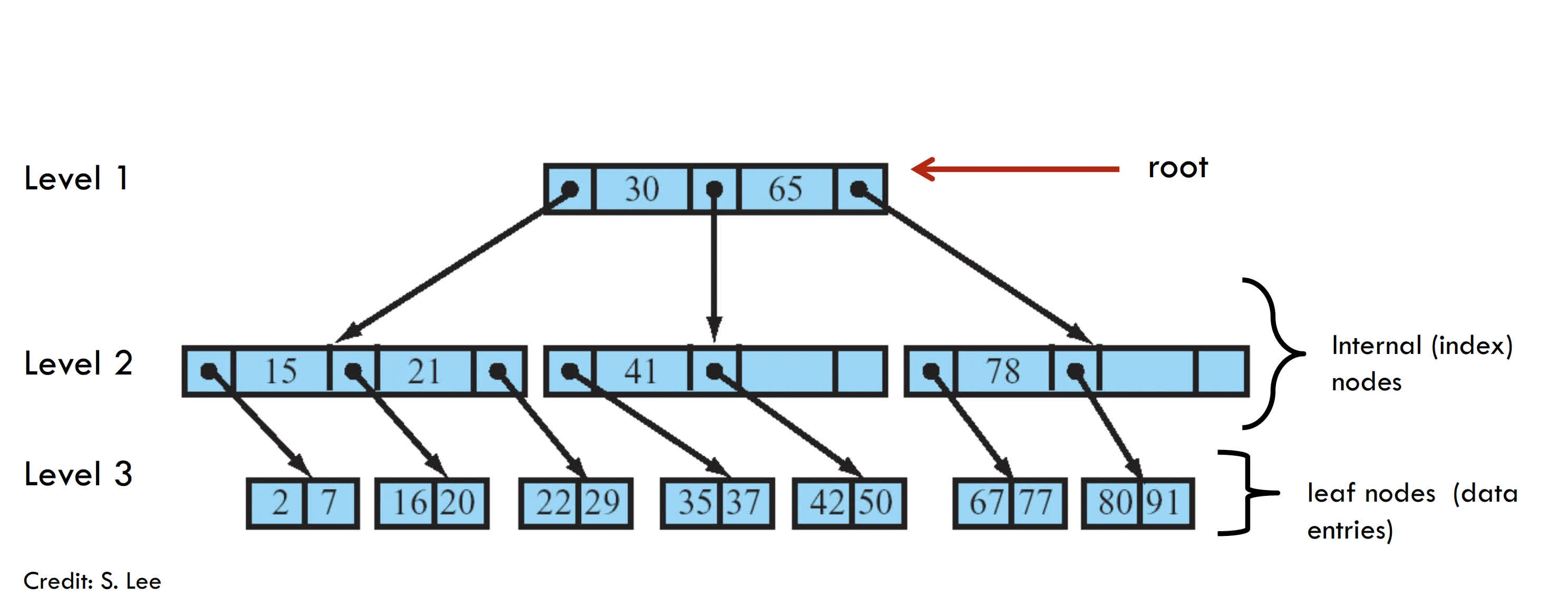
DS: B+ Tree Index or Hash-based Index
B+ Tree
note: each node are at least 50% full
cost
tree is “height-balanced”
insert/delete at logFN cost
min 50% occupancy, each node contains d≤m≤2d entries, where d is the order or the tree
insert a data entry
find correct leaf L
put data entry onto L
if L has enough space ⇒ done!
splitL
redistribute entries evenly, copy up middle key
insert index entry point to L2 in parent of L
split grow trees, root split increase heights
delete a data entry
find leaf L where entry belongs
remove entry
if L is at least half-full ⇒ done!
if not
redistribute, borrowing from sibling (adjacent node with same parent of L)
if fails, merge and sibling
merge occured then delete entry (point to L or sibling) from parent of L
merge propagate root, decrease heights
Hash-based Index
index is a collection of buckets
Insert: if bucket is full ⇒split
Alternatives for data entries
How
By Value
record contents are stored in index file (no need to follow pointers)
 Left outer join
Left outer join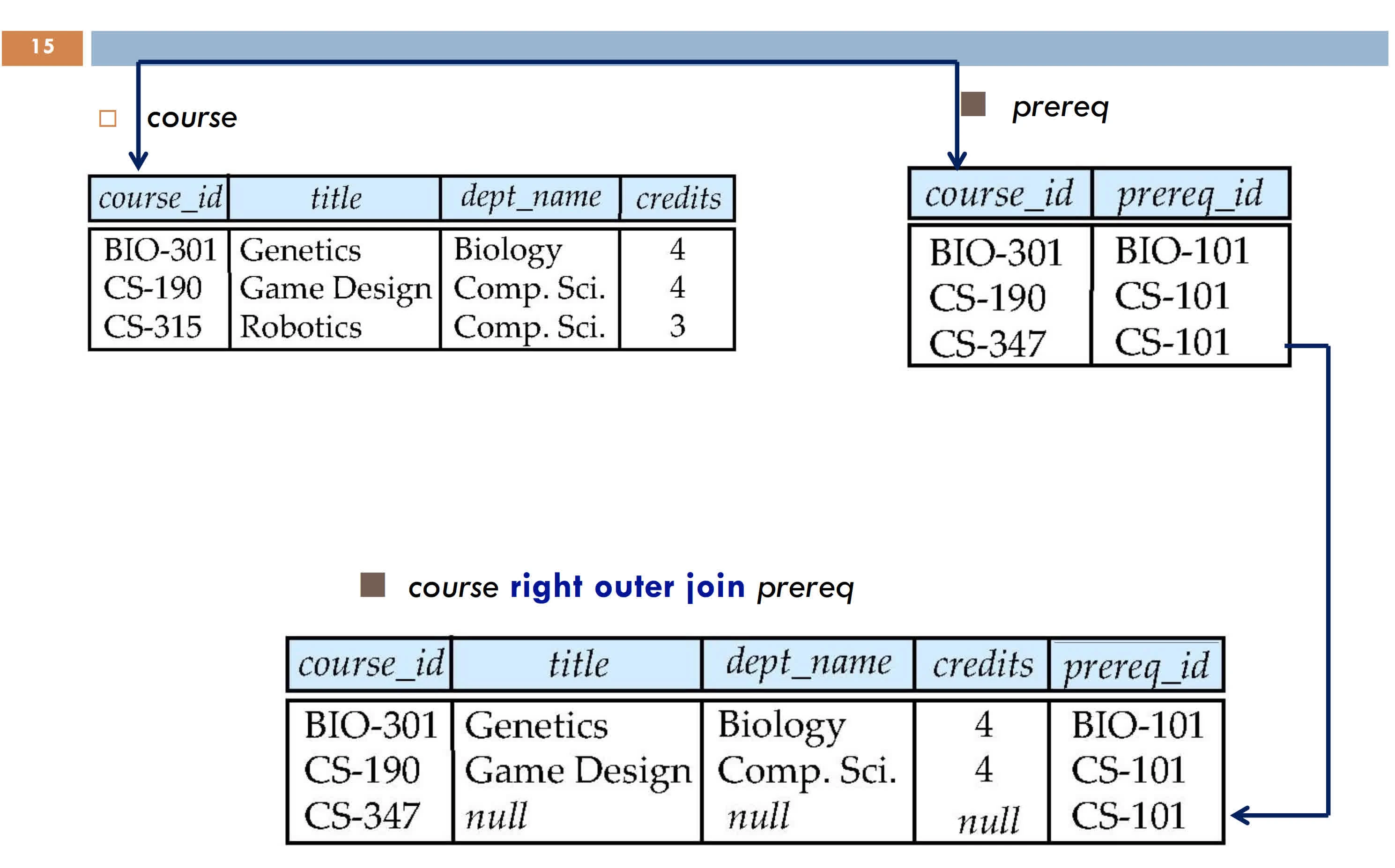 Right outer join
Right outer join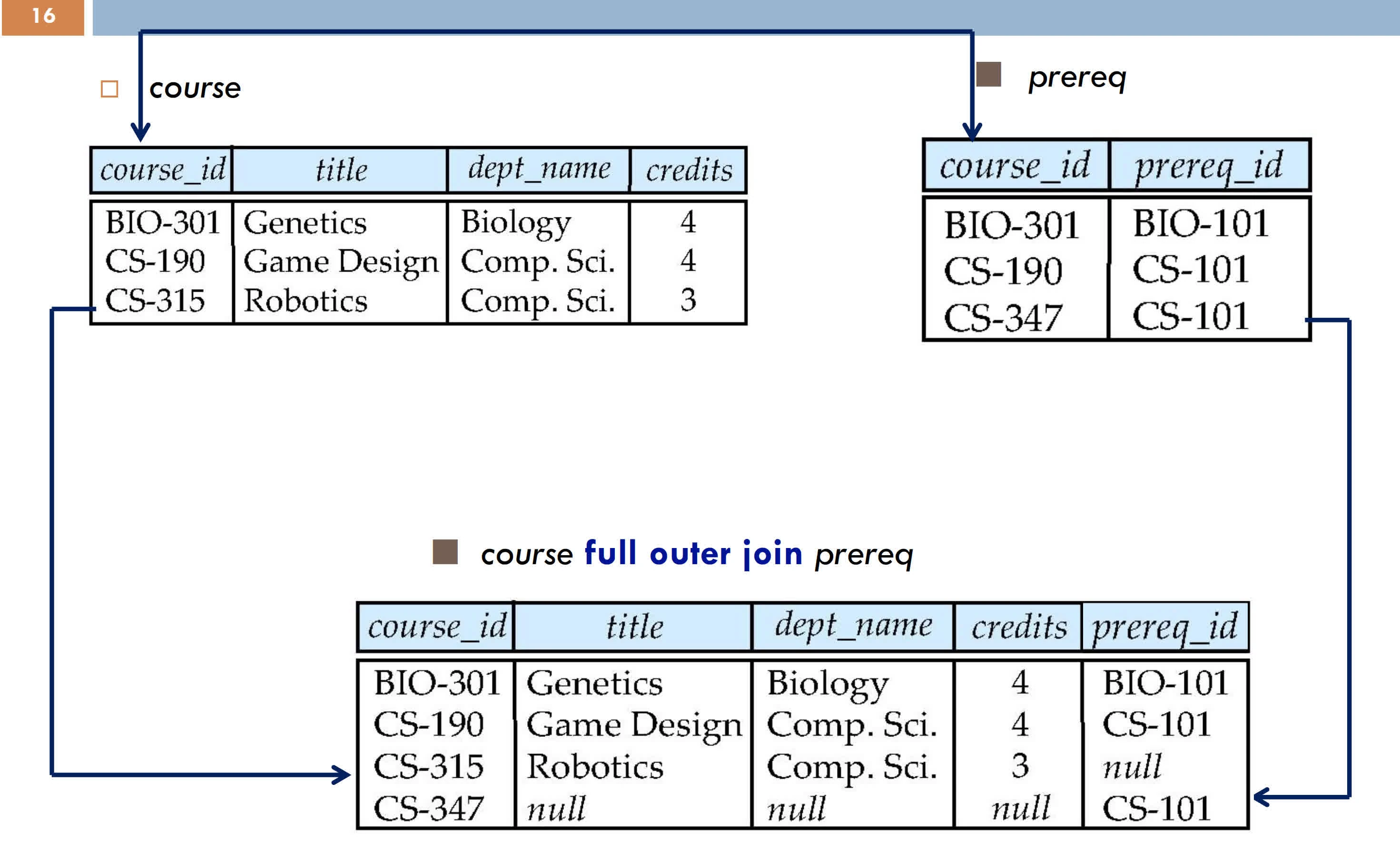 full outer join
full outer join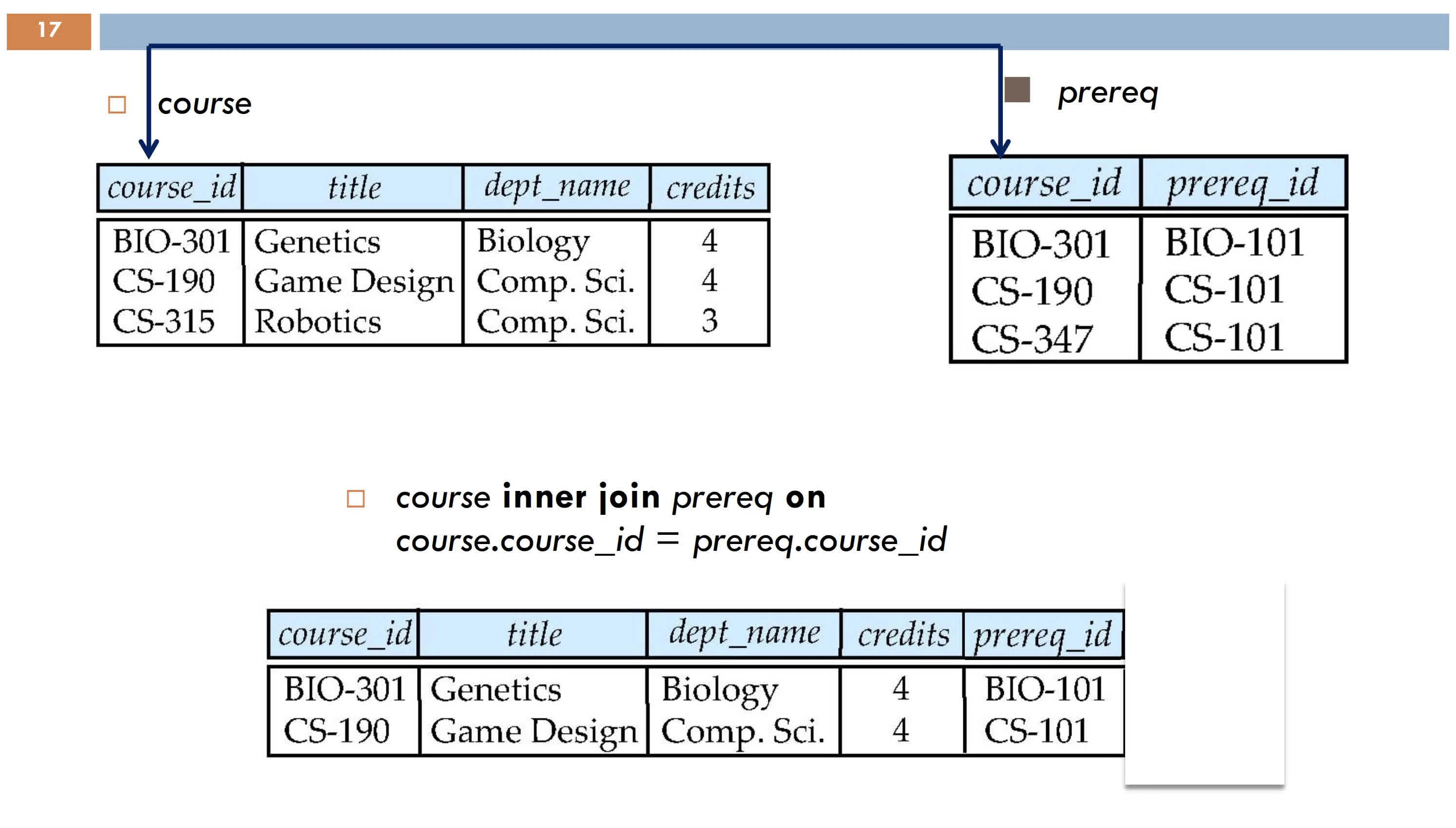 inner join
inner join