Connectionist networks See also
bayes rules and chain rules Joint distribution: P ( X , Y ) P(X,Y) P ( X , Y )
Conditional distribution of X X X Y Y Y P ( X ∣ Y ) = P ( X , Y ) P ( Y ) P(X|Y) = \frac{P(X,Y)}{P(Y)} P ( X ∣ Y ) = P ( Y ) P ( X , Y )
Bayes rule: P ( X ∣ Y ) = P ( Y ∣ X ) P ( X ) P ( Y ) P(X|Y) = \frac{P(Y|X)P(X)}{P(Y)} P ( X ∣ Y ) = P ( Y ) P ( Y ∣ X ) P ( X )
Chain rule:
for two events:
P ( A , B ) = P ( B ∣ A ) P ( A ) P(A, B) = P(B \mid A)P(A) P ( A , B ) = P ( B ∣ A ) P ( A ) generalised:
P ( X 1 , X 2 , … , X k ) = P ( X 1 ) ∏ j = 2 n P ( X j ∣ X 1 , … , X j − 1 ) ∵ expansion: P ( X 1 ) P ( X 2 ∣ X 1 ) … P ( X k ∣ X 1 , X 2 , … , X k − 1 ) \begin{aligned}
&P(X_1, X_2, \ldots , X_k) \\
&= P(X_1) \prod_{j=2}^{n} P(X_j \mid X_1,\dots,X_{j-1}) \\[12pt]
&\because \text{expansion: }P(X_1)P(X_2|X_1)\ldots P(X_k|X_1,X_2,\ldots,X_{k-1})
\end{aligned} P ( X 1 , X 2 , … , X k ) = P ( X 1 ) j = 2 ∏ n P ( X j ∣ X 1 , … , X j − 1 ) ∵ expansion: P ( X 1 ) P ( X 2 ∣ X 1 ) … P ( X k ∣ X 1 , X 2 , … , X k − 1 )
assume underlying distribution D D D
Example: flip a coin
Outcome H = 0 H=0 H = 0 T = 1 T=1 T = 1 P ( H ) = p P(H) = p P ( H ) = p P ( T ) = 1 − p P(T) = 1-p P ( T ) = 1 − p x ∈ { 0 , 1 } x \in \{0,1\} x ∈ { 0 , 1 } x x x
P ( x = 0 ) = α P(x=0)=\alpha P ( x = 0 ) = α P ( x = 1 ) = 1 − α P(x=1)=1-\alpha P ( x = 1 ) = 1 − α
Note that for any random variables A , B , C A,B,C A , B , C
P ( A , B ∣ C ) = P ( A ∣ B , C ) P ( B ∣ C ) P(A,B \mid C) = P(A\mid B,C) P(B \mid C) P ( A , B ∣ C ) = P ( A ∣ B , C ) P ( B ∣ C ) See also:
expected error minimisation think of it as bias-variance tradeoff
Squared loss: l ( y ^ , y ) = ( y − y ^ ) 2 l(\hat{y},y)=(y-\hat{y})^2 l ( y ^ , y ) = ( y − y ^ ) 2
solution to y ∗ = arg min y ^ E X , Y ( Y − y ^ ( X ) ) 2 y^* = \argmin_{\hat{y}} E_{X,Y}(Y-\hat{y}(X))^2 y ∗ = y ^ arg min E X , Y ( Y − y ^ ( X ) ) 2 E [ Y ∣ X = x ] E[Y | X=x] E [ Y ∣ X = x ]
Instead we have Z = { ( x i , y i ) } i = 1 n Z = \{(x^i, y^i)\}^n_{i=1} Z = {( x i , y i ) } i = 1 n
error decomposition E x , y ( y − y Z ^ ( x ) ) 2 = E x y ( y − y ∗ ( x ) ) 2 + E x ( y ∗ ( x ) − y Z ^ ( x ) ) 2 = noise + estimation error \begin{aligned}
&E_{x,y}(y-\hat{y_Z}(x))^2 \\
&= E_{xy}(y-y^{*}(x))^2 + E_x(y^{*}(x) - \hat{y_Z}(x))^2 \\
&= \text{noise} + \text{estimation error}
\end{aligned} E x , y ( y − y Z ^ ( x ) ) 2 = E x y ( y − y ∗ ( x ) ) 2 + E x ( y ∗ ( x ) − y Z ^ ( x ) ) 2 = noise + estimation error bias-variance decompositions For linear estimator:
E Z E x , y ( y − ( y ^ Z ( x ) ≔ W Z T x ) ) 2 = E x , y ( y − y ∗ ( x ) ) 2 noise + E x ( y ∗ ( x ) − E Z ( y Z ^ ( x ) ) ) 2 bias + E x E Z ( y Z ^ ( x ) − E Z ( y Z ^ ( x ) ) ) 2 variance \begin{aligned}
E_Z&E_{x,y}(y-(\hat{y}_Z(x)\coloneqq W^T_Zx))^2 \\
=& E_{x,y}(y-y^{*}(x))^2 \quad \text{noise} \\
&+ E_x(y^{*}(x) - E_Z(\hat{y_Z}(x)))^2 \quad \text{bias} \\
&+ E_xE_Z(\hat{y_Z}(x) - E_Z(\hat{y_Z}(x)))^2 \quad \text{variance}
\end{aligned} E Z = E x , y ( y − ( y ^ Z ( x ) : = W Z T x ) ) 2 E x , y ( y − y ∗ ( x ) ) 2 noise + E x ( y ∗ ( x ) − E Z ( y Z ^ ( x )) ) 2 bias + E x E Z ( y Z ^ ( x ) − E Z ( y Z ^ ( x )) ) 2 variance accuracy zero-one loss:
l 0 − 1 ( y , y ^ ) = 1 y ≠ y ^ = { 1 y ≠ y ^ 0 y = y ^ l^{0-1}(y, \hat{y}) = 1_{y \neq \hat{y}}= \begin{cases} 1 & y \neq \hat{y} \\\ 0 & y = \hat{y} \end{cases} l 0 − 1 ( y , y ^ ) = 1 y = y ^ = { 1 0 y = y ^ y = y ^ linear classifier y ^ W ( x ) = sign ( W T x ) = 1 W T x ≥ 0 ∵ W ^ = arg min W L Z 0 − 1 ( y ^ W ) \begin{aligned}
\hat{y}_W(x) &= \text{sign}(W^T x) = 1_{W^T x \geq 0} \\[8pt]
&\because \hat{W} = \argmin_{W} L_{Z}^{0-1} (\hat{y}_W)
\end{aligned} y ^ W ( x ) = sign ( W T x ) = 1 W T x ≥ 0 ∵ W ^ = W arg min L Z 0 − 1 ( y ^ W ) surrogate loss functions assume classifier returns a discrete value y ^ W = sign ( W T x ) ∈ { 0 , 1 } \hat{y}_W = \text{sign}(W^T x) \in \{0,1\} y ^ W = sign ( W T x ) ∈ { 0 , 1 }
What if classifier's output is continuous?
y ^ \hat{y} y ^
Think of contiguous loss function: margin loss, cross-entropy/negative log-likelihood, etc.
linearly separable data
A binary classification data set Z = { ( x i , y i ) } i = 1 n Z=\{(x^i, y^i)\}_{i=1}^{n} Z = {( x i , y i ) } i = 1 n W ∗ W^{*} W ∗
∀ i ∈ [ n ] ∣ SGN ( < x i , W ∗ > ) = y i \forall i \in [n] \mid \text{SGN}(<x^i, W^{*}>) = y^i ∀ i ∈ [ n ] ∣ SGN ( < x i , W ∗ > ) = y i Or, for every i ∈ [ n ] i \in [n] i ∈ [ n ] ( W ∗ T x i ) y i > 0 (W^{* T}x^i)y^i > 0 ( W ∗ T x i ) y i > 0
linear programming max W ∈ R d ⟨ u , w ⟩ = ∑ i = 1 d u i w i s.t A w ≥ v \begin{aligned}
\max_{W \in \mathbb{R}^d} &\langle{u, w} \rangle = \sum_{i=1}^{d} u_i w_i \\
&\text{s.t } A w \ge v
\end{aligned} W ∈ R d max ⟨ u , w ⟩ = i = 1 ∑ d u i w i s.t A w ≥ v Given that data is linearly separable
∃ W ∗ ∣ ∀ i ∈ [ n ] , ( W ∗ T x i ) y i > 0 ∃ W ∗ , γ > 0 ∣ ∀ i ∈ [ n ] , ( W ∗ T x i ) y i ≥ γ ∃ W ∗ ∣ ∀ i ∈ [ n ] , ( W ∗ T x i ) y i ≥ 1 \begin{aligned}
\exists \space W^{*} &\mid \forall i \in [n], ({W^{*}}^T x^i)y^i > 0 \\
\exists \space W^{*}, \gamma > 0 &\mid \forall i \in [n], ({W^{*}}^T x^i)y^i \ge \gamma \\
\exists \space W^{*} &\mid \forall i \in [n], ({W^{*}}^T x^i)y^i \ge 1
\end{aligned} ∃ W ∗ ∃ W ∗ , γ > 0 ∃ W ∗ ∣ ∀ i ∈ [ n ] , ( W ∗ T x i ) y i > 0 ∣ ∀ i ∈ [ n ] , ( W ∗ T x i ) y i ≥ γ ∣ ∀ i ∈ [ n ] , ( W ∗ T x i ) y i ≥ 1 LP for linear classification perceptron Rosenblatt’s perceptron algorithm
"\\begin{algorithm}\n\\caption{Batch Perceptron}\n\\begin{algorithmic}\n\\REQUIRE Training set $(\\mathbf{x}_1, y_1),\\ldots,(\\mathbf{x}_m, y_m)$\n\\STATE Initialize $\\mathbf{w}^{(1)} = (0,\\ldots,0)$\n\\FOR{$t = 1,2,\\ldots$}\n \\IF{$(\\exists \\space i \\text{ s.t. } y_i\\langle\\mathbf{w}^{(t)}, \\mathbf{x}_i\\rangle \\leq 0)$}\n \\STATE $\\mathbf{w}^{(t+1)} = \\mathbf{w}^{(t)} + y_i\\mathbf{x}_i$\n \\ELSE\n \\STATE \\textbf{output} $\\mathbf{w}^{(t)}$\n \\ENDIF\n\\ENDFOR\n\\end{algorithmic}\n\\end{algorithm}"
Algorithm 1 Batch Perceptron
Require: Training set ( x 1 , y 1 ) , … , ( x m , y m ) (\mathbf{x}_1, y_1),\ldots,(\mathbf{x}_m, y_m) ( x 1 , y 1 ) , … , ( x m , y m )
1: Initialize w ( 1 ) = ( 0 , … , 0 ) \mathbf{w}^{(1)} = (0,\ldots,0) w ( 1 ) = ( 0 , … , 0 )
2: for t = 1 , 2 , … t = 1,2,\ldots t = 1 , 2 , … do
3: if ( ∃ i s.t. y i ⟨ w ( t ) , x i ⟩ ≤ 0 ) (\exists \space i \text{ s.t. } y_i\langle\mathbf{w}^{(t)}, \mathbf{x}_i\rangle \leq 0) ( ∃ i s.t. y i ⟨ w ( t ) , x i ⟩ ≤ 0 ) then
4: w ( t + 1 ) = w ( t ) + y i x i \mathbf{w}^{(t+1)} = \mathbf{w}^{(t)} + y_i\mathbf{x}_i w ( t + 1 ) = w ( t ) + y i x i
5: else
6: output w ( t ) \mathbf{w}^{(t)} w ( t )
7: end if
8: end for
greedy update W new T x i y i = ⟨ W old + y i x i , x i ⟩ y i = W old T x i y i + ∥ x i ∥ 2 2 y i y i \begin{aligned}
W_{\text{new}}^T x^i y^i &= \langle W_{\text{old}}+ y^i x^i, x^i \rangle y^i \\
&=W_{\text{old}}^T x^{i} y^{i} + \|x^i\|_2^2 y^{i} y^{i}
\end{aligned} W new T x i y i = ⟨ W old + y i x i , x i ⟩ y i = W old T x i y i + ∥ x i ∥ 2 2 y i y i proof See also (
Assume there exists some parameter vector θ ‾ ∗ \underline{\theta}^{*} θ ∗ ∥ θ ‾ ∗ ∥ = 1 \|\underline{\theta}^{*}\| = 1 ∥ θ ∗ ∥ = 1 ∃ γ > 0 s.t \exists \space \upgamma > 0 \text{ s.t } ∃ γ > 0 s.t
y t ( x t ‾ ⋅ θ ∗ ‾ ) ≥ γ y_t(\underline{x_t} \cdot \underline{\theta^{*}}) \ge \upgamma y t ( x t ⋅ θ ∗ ) ≥ γ Assumption : ∀ t = 1 … n , ∥ x t ‾ ∥ ≤ R \forall \space t= 1 \ldots n, \|\underline{x_t}\| \le R ∀ t = 1 … n , ∥ x t ∥ ≤ R
Then perceptron makes at most R 2 γ 2 \frac{R^2}{\upgamma^2} γ 2 R 2
proof by induction
definition of θ k ‾ \underline{\theta^k} θ k
to be parameter vector where algorithm makes k th k^{\text{th}} k th
Note that we have θ 1 ‾ = 0 ‾ \underline{\theta^{1}}=\underline{0} θ 1 = 0
Assume that k th k^{\text{th}} k th t t t
θ k + 1 ‾ ⋅ θ ∗ ‾ = ( θ k ‾ + y t x t ‾ ) ⋅ θ ∗ ‾ = θ k ‾ ⋅ θ ∗ ‾ + y t x t ‾ ⋅ θ ∗ ‾ ≥ θ k ‾ ⋅ θ ∗ ‾ + γ ∵ Assumption: y t x t ‾ ⋅ θ ∗ ‾ ≥ γ \begin{align}
\underline{\theta^{k+1}} \cdot \underline{\theta^{*}} &= (\underline{\theta^k} + y_t \underline{x_t}) \cdot \underline{\theta^{*}} \\
&= \underline{\theta^k} \cdot \underline{\theta^{*}} + y_t \underline{x^t} \cdot \underline{\theta^{*}} \\
&\ge \underline{\theta^k} \cdot \underline{\theta^{*}} + \upgamma \\[12pt]
&\because \text{ Assumption: } y_t \underline{x_t} \cdot \underline{\theta^{*}} \ge \upgamma
\end{align} θ k + 1 ⋅ θ ∗ = ( θ k + y t x t ) ⋅ θ ∗ = θ k ⋅ θ ∗ + y t x t ⋅ θ ∗ ≥ θ k ⋅ θ ∗ + γ ∵ Assumption: y t x t ⋅ θ ∗ ≥ γ Follows up by induction on k k k
θ k + 1 ‾ ⋅ θ ∗ ‾ ≥ k γ \underline{\theta^{k+1}} \cdot \underline{\theta^{*}} \ge k \upgamma θ k + 1 ⋅ θ ∗ ≥ kγ Using ∥ θ k + 1 ‾ ∥ × ∥ θ ∗ ‾ ∥ ≥ θ k + 1 ‾ ⋅ θ ∗ ‾ \|\underline{\theta^{k+1}}\| \times \|\underline{\theta^{*}}\| \ge \underline{\theta^{k+1}} \cdot \underline{\theta^{*}} ∥ θ k + 1 ∥ × ∥ θ ∗ ∥ ≥ θ k + 1 ⋅ θ ∗
∥ θ k + 1 ‾ ∥ ≥ k γ ∵ ∥ θ ∗ ‾ ∥ = 1 \begin{align}
\|\underline{\theta^{k+1}}\| &\ge k \upgamma \\[16pt]
&\because \|\underline{\theta^{*}}\| = 1
\end{align} ∥ θ k + 1 ∥ ≥ kγ ∵ ∥ θ ∗ ∥ = 1 In the second part, we will find upper bound for (5):
∥ θ k + 1 ‾ ∥ 2 = ∥ θ k ‾ + y t x t ‾ ∥ 2 = ∥ θ k ‾ ∥ 2 + y t 2 ∥ x t ‾ ∥ 2 + 2 y t x t ‾ ⋅ θ k ‾ ≤ ∥ θ k ‾ ∥ 2 + R 2 \begin{align}
\|\underline{\theta^{k+1}}\|^2 &= \|\underline{\theta^k} + y_t \underline{x_t}\|^2 \\
&= \|\underline{\theta^k}\|^2 + y_t^2 \|\underline{x_t}\|^2 + 2 y_t \underline{x_t} \cdot \underline{\theta^k} \\
&\le \|\underline{\theta^k}\|^2 + R^2
\end{align} ∥ θ k + 1 ∥ 2 = ∥ θ k + y t x t ∥ 2 = ∥ θ k ∥ 2 + y t 2 ∥ x t ∥ 2 + 2 y t x t ⋅ θ k ≤ ∥ θ k ∥ 2 + R 2 (9) is due to:
y t 2 ∥ x t ‾ 2 ∥ 2 = ∥ x t ‾ 2 ∥ ≤ R 2 y_t^2 \|\underline{x_t}^2\|^2 = \|\underline{x_t}^2\| \le R^2 y t 2 ∥ x t 2 ∥ 2 = ∥ x t 2 ∥ ≤ R 2 y t x t ‾ ⋅ θ k ‾ ≤ 0 y_t \underline{x_t} \cdot \underline{\theta^k} \le 0 y t x t ⋅ θ k ≤ 0 θ k ‾ \underline{\theta^k} θ k t th t^{\text{th}} t th
Follows with induction on k k k
∥ θ k + 1 ‾ ∥ 2 ≤ k R 2 \begin{align}
\|\underline{\theta^{k+1}}\|^2 \le kR^2
\end{align} ∥ θ k + 1 ∥ 2 ≤ k R 2 from (5) and (10) gives us
k 2 γ 2 ≤ ∥ θ k + 1 ‾ ∥ 2 ≤ k R 2 k ≤ R 2 γ 2 \begin{aligned}
k^2 \upgamma^2 &\le \|\underline{\theta^{k+1}}\|^2 \le kR^2 \\
k &\le \frac{R^2}{\upgamma^2}
\end{aligned} k 2 γ 2 k ≤ ∥ θ k + 1 ∥ 2 ≤ k R 2 ≤ γ 2 R 2 idea: maximises margin and more robust to “perturbations”
Euclidean distance between two points x x x W W W
∣ W T x + b ∣ ∥ W ∥ 2 \frac{\mid W^T x + b \mid }{\|W\|_2} ∥ W ∥ 2 ∣ W T x + b ∣
Assuming ∥ W ∥ 2 = 1 \| W \|_2=1 ∥ W ∥ 2 = 1 ∣ W T x + b ∣ \mid W^T x + b \mid ∣ W T x + b ∣
SVMs are good for high-dimensional data
We can probably use a solver, or
maximum margin hyperplane W W W γ \gamma γ
W T x + b ≥ γ ∀ blue x W T x + b ≤ − γ ∀ red x \begin{aligned}
W^T x + b \ge \gamma \space &\forall \text{ blue x} \\
W^T x +b \le - \gamma \space &\forall \text{ red x}
\end{aligned} W T x + b ≥ γ W T x + b ≤ − γ ∀ blue x ∀ red x Margin:
Z = { ( x i , y i ) } i = 1 n , y ∈ { − 1 , 1 } , ∥ W ∥ 2 = 1 Z = \{(x^{i}, y^{i})\}_{i=1}^{n}, y \in \{-1, 1\}, \|W\|_2 = 1 Z = {( x i , y i ) } i = 1 n , y ∈ { − 1 , 1 } , ∥ W ∥ 2 = 1 hard-margin SVM this is the version with bias
"\\begin{algorithm}\n\\caption{Hard-SVM}\n\\begin{algorithmic}\n\\REQUIRE Training set $(\\mathbf{x}_1, y_1),\\ldots,(\\mathbf{x}_m, y_m)$\n\\STATE \\textbf{solve:} $(w_{0},b_{0}) = \\argmin\\limits_{(w,b)} \\|w\\|^2 \\text{ s.t } \\forall i, y_{i}(\\langle{w,x_i} \\rangle + b) \\ge 1$\n\\STATE \\textbf{output:} $\\hat{w} = \\frac{w_0}{\\|w_0\\|}, \\hat{b} = \\frac{b_0}{\\|w_0\\|}$\n\\end{algorithmic}\n\\end{algorithm}"
Algorithm 6 Hard-SVM
Require: Training set ( x 1 , y 1 ) , … , ( x m , y m ) (\mathbf{x}_1, y_1),\ldots,(\mathbf{x}_m, y_m) ( x 1 , y 1 ) , … , ( x m , y m )
1: solve: ( w 0 , b 0 ) = arg min ( w , b ) ∥ w ∥ 2 s.t ∀ i , y i ( ⟨ w , x i ⟩ + b ) ≥ 1 (w_{0},b_{0}) = \argmin\limits_{(w,b)} \|w\|^2 \text{ s.t } \forall i, y_{i}(\langle{w,x_i} \rangle + b) \ge 1 ( w 0 , b 0 ) = ( w , b ) arg min ∥ w ∥ 2 s.t ∀ i , y i (⟨ w , x i ⟩ + b ) ≥ 1
2: output: w ^ = w 0 ∥ w 0 ∥ , b ^ = b 0 ∥ w 0 ∥ \hat{w} = \frac{w_0}{\|w_0\|}, \hat{b} = \frac{b_0}{\|w_0\|} w ^ = ∥ w 0 ∥ w 0 , b ^ = ∥ w 0 ∥ b 0
Note that this version is sensitive to outliers
it assumes that training set is linearly separable
soft-margin SVM can be applied even if the training set is not linearly separable
"\\begin{algorithm}\n\\caption{Soft-SVM}\n\\begin{algorithmic}\n\\REQUIRE Input $(\\mathbf{x}_1, y_1),\\ldots,(\\mathbf{x}_m, y_m)$\n\\STATE \\textbf{parameter:} $\\lambda > 0$\n\\STATE \\textbf{solve:} $\\min_{\\mathbf{w}, b, \\boldsymbol{\\xi}} \\left( \\lambda \\|\\mathbf{w}\\|^2 + \\frac{1}{m} \\sum_{i=1}^m \\xi_i \\right)$\n\\STATE \\textbf{s.t: } $\\forall i, \\quad y_i (\\langle \\mathbf{w}, \\mathbf{x}_i \\rangle + b) \\geq 1 - \\xi_i \\quad \\text{and} \\quad \\xi_i \\geq 0$\n\\STATE \\textbf{output:} $\\mathbf{w}, b$\n\\end{algorithmic}\n\\end{algorithm}"
Algorithm 7 Soft-SVM
Require: Input ( x 1 , y 1 ) , … , ( x m , y m ) (\mathbf{x}_1, y_1),\ldots,(\mathbf{x}_m, y_m) ( x 1 , y 1 ) , … , ( x m , y m )
1: parameter: λ > 0 \lambda > 0 λ > 0
2: solve: min w , b , ξ ( λ ∥ w ∥ 2 + 1 m ∑ i = 1 m ξ i ) \min_{\mathbf{w}, b, \boldsymbol{\xi}} \left( \lambda \|\mathbf{w}\|^2 + \frac{1}{m} \sum_{i=1}^m \xi_i \right) min w , b , ξ ( λ ∥ w ∥ 2 + m 1 ∑ i = 1 m ξ i )
3: s.t: ∀ i , y i ( ⟨ w , x i ⟩ + b ) ≥ 1 − ξ i and ξ i ≥ 0 \forall i, \quad y_i (\langle \mathbf{w}, \mathbf{x}_i \rangle + b) \geq 1 - \xi_i \quad \text{and} \quad \xi_i \geq 0 ∀ i , y i (⟨ w , x i ⟩ + b ) ≥ 1 − ξ i and ξ i ≥ 0
4: output: w , b \mathbf{w}, b w , b
Equivalent form of soft-margin SVM:
min w ( λ ∥ w ∥ 2 + L S hinge ( w ) ) L S hinge ( w ) = 1 m ∑ i = 1 m max ( { 0 , 1 − y ⟨ w , x i ⟩ } ) \begin{aligned}
\min_{w} &(\lambda \|w\|^2 + L_S^{\text{hinge}}(w)) \\[8pt]
L_{S}^{\text{hinge}}(w) &= \frac{1}{m} \sum_{i=1}^{m} \max{(\{0, 1 - y \langle w, x_i \rangle\})}
\end{aligned} w min L S hinge ( w ) ( λ ∥ w ∥ 2 + L S hinge ( w )) = m 1 i = 1 ∑ m max ({ 0 , 1 − y ⟨ w , x i ⟩}) SVM with basis functions min W 1 n ∑ max { 0 , 1 − y i ⟨ w , ϕ ( x i ) ⟩ } + λ ∥ w ∥ 2 2 \min_{W} \frac{1}{n} \sum \max \{0, 1 - y^i \langle w, \phi(x^i) \rangle\} + \lambda \|w\|^2_2 W min n 1 ∑ max { 0 , 1 − y i ⟨ w , ϕ ( x i )⟩} + λ ∥ w ∥ 2 2
ϕ ( x i ) \phi(x^i) ϕ ( x i )
representor theorem W ∗ = arg min W 1 n ∑ max { 0 , 1 − y i ⟨ w , ϕ ( x i ) ⟩ } + λ ∥ w ∥ 2 2 W^{*} = \argmin_{W} \frac{1}{n} \sum \max \{0, 1- y^i \langle w, \phi (x^i) \rangle\} + \lambda \|w\|^2_2 W ∗ = W arg min n 1 ∑ max { 0 , 1 − y i ⟨ w , ϕ ( x i )⟩} + λ ∥ w ∥ 2 2
There are real values a 1 , … , a m a_{1},\ldots,a_{m} a 1 , … , a m
W ∗ = ∑ a i ϕ ( x i ) W^{*} = \sum a_i \phi(x^i) W ∗ = ∑ a i ϕ ( x i )
kernelized SVM from
K ( x , z ) = ⟨ ϕ ( x ) , ϕ ( z ) ⟩ K(x,z) = \langle \phi(x), \phi(z) \rangle K ( x , z ) = ⟨ ϕ ( x ) , ϕ ( z )⟩ drawbacks
prediction-time complexity
need to store all training data
Dealing with K n × n \mathbf{K}_{n \times n} K n × n
choice of kernel, in which is tricky and pretty heuristic sometimes.
minimize squared error Given a homogeneous line y = a x y = ax y = a x f ( x ) = x 2 + 1 f(x) = x^2 +1 f ( x ) = x 2 + 1 a , y , x ∈ R a,y,x \in \mathbb{R} a , y , x ∈ R
assuming x are uniformly distributed on [ 0 , 1 ] [0,1] [ 0 , 1 ]
arg min α E [ ( a x − x 2 − 1 ) 2 ] \argmin_{\alpha} E[(ax - x^2 - 1)^2] α arg min E [( a x − x 2 − 1 ) 2 ] or we need to find
arg min α ∫ − ∞ ∞ P X ( x ) ( a x − x 2 − 1 ) 2 d x \argmin_{\alpha} \int_{-\infty}^{\infty} P_X(x) (ax - x^2 -1)^2 dx α arg min ∫ − ∞ ∞ P X ( x ) ( a x − x 2 − 1 ) 2 d x multi-variate chain rule ∇ x f ⊙ g ( x ) = [ ∇ g ] d × m ⋅ [ ∇ f ] m × n \nabla_x f \odot g(x) = [\nabla_g]_{d \times m} \cdot [\nabla_f]_{m \times n} ∇ x f ⊙ g ( x ) = [ ∇ g ] d × m ⋅ [ ∇ f ] m × n Or we can find the J f \mathcal{J}_f J f
if f = A x f = Ax f = A x ∇ f = A \nabla_f = A ∇ f = A
classification or on-versus-all classification
idea: train k k k
h i ( x ) = sgn ( ⟨ w i , x ⟩ ) h_i(x) = \text{sgn}(\langle w_i, x \rangle) h i ( x ) = sgn (⟨ w i , x ⟩) end-to-end version, or multi-class SVM with generalized Hinge loss:
"\\begin{algorithm}\n\\caption{Multiclass SVM}\n\\begin{algorithmic}\n\\REQUIRE Input $(\\mathbf{x}_1, y_1),\\ldots,(\\mathbf{x}_m, y_m)$\n\\REQUIRE\n \\STATE Regularization parameter $\\lambda > 0$\n \\STATE Loss function $\\Delta: \\mathcal{Y} \\times \\mathcal{Y} \\to \\mathbb{R}_+$\n \\STATE Class-sensitive feature mapping $\\Psi: \\mathcal{X} \\times \\mathcal{Y} \\to \\mathbb{R}^d$\n\\ENSURE\n\\STATE \\textbf{solve}: $\\min_{\\mathbf{w} \\in \\mathbb{R}^d} \\left(\\lambda\\|\\mathbf{w}\\|^2 + \\frac{1}{m}\\sum_{i=1}^m \\max_{y' \\in \\mathcal{Y}} \\left(\\Delta(y', y_i) + \\langle\\mathbf{w}, \\Psi(\\mathbf{x}_i, y') - \\Psi(\\mathbf{x}_i, y_i)\\rangle\\right)\\right)$\n\\STATE \\textbf{output}: the predictor $h_{\\mathbf{w}}(\\mathbf{x}) = \\argmax_{y \\in \\mathcal{Y}} \\langle\\mathbf{w}, \\Psi(\\mathbf{x}, y)\\rangle$\n\\end{algorithmic}\n\\end{algorithm}"
Algorithm 8 Multiclass SVM
Require: Input ( x 1 , y 1 ) , … , ( x m , y m ) (\mathbf{x}_1, y_1),\ldots,(\mathbf{x}_m, y_m) ( x 1 , y 1 ) , … , ( x m , y m )
Require:
1: Regularization parameter λ > 0 \lambda > 0 λ > 0
2: Loss function Δ : Y × Y → R + \Delta: \mathcal{Y} \times \mathcal{Y} \to \mathbb{R}_+ Δ : Y × Y → R +
3: Class-sensitive feature mapping Ψ : X × Y → R d \Psi: \mathcal{X} \times \mathcal{Y} \to \mathbb{R}^d Ψ : X × Y → R d
Ensure:
4: solve : min w ∈ R d ( λ ∥ w ∥ 2 + 1 m ∑ i = 1 m max y ′ ∈ Y ( Δ ( y ′ , y i ) + ⟨ w , Ψ ( x i , y ′ ) − Ψ ( x i , y i ) ⟩ ) ) \min_{\mathbf{w} \in \mathbb{R}^d} \left(\lambda\|\mathbf{w}\|^2 + \frac{1}{m}\sum_{i=1}^m \max_{y' \in \mathcal{Y}} \left(\Delta(y', y_i) + \langle\mathbf{w}, \Psi(\mathbf{x}_i, y') - \Psi(\mathbf{x}_i, y_i)\rangle\right)\right) min w ∈ R d ( λ ∥ w ∥ 2 + m 1 ∑ i = 1 m max y ′ ∈ Y ( Δ ( y ′ , y i ) + ⟨ w , Ψ ( x i , y ′ ) − Ψ ( x i , y i )⟩ ) )
5: output : the predictor h w ( x ) = arg max y ∈ Y ⟨ w , Ψ ( x , y ) ⟩ h_{\mathbf{w}}(\mathbf{x}) = \argmax_{y \in \mathcal{Y}} \langle\mathbf{w}, \Psi(\mathbf{x}, y)\rangle h w ( x ) = arg max y ∈ Y ⟨ w , Ψ ( x , y )⟩
all-pairs classification For each distinct i , j ∈ { 1 , 2 , … , k } i,j \in \{1,2,\ldots,k\} i , j ∈ { 1 , 2 , … , k } i i i j j j
h i , j ( x ) = sgn ( ⟨ w i , j , x ⟩ ) h_{i,j}(x) = \text{sgn}(\langle w_{i,j}, x \rangle) h i , j ( x ) = sgn (⟨ w i , j , x ⟩) linear multi-class predictor think of multi-vector encoding for y ∈ { 1 , 2 , … , k } y \in \{1,2,\ldots,k\} y ∈ { 1 , 2 , … , k } ( x , y ) (x,y) ( x , y ) Ψ ( x , y ) = [ 0 … 0 x 0 … 0 ] T \Psi(x,y) = [0 \space \ldots \space 0 \space x \space 0 \space \ldots \space 0]^T Ψ ( x , y ) = [ 0 … 0 x 0 … 0 ] T
thus our generalized Hinge loss now becomes:
h ( x ) = arg max y ⟨ w , Ψ ( x , y ) ⟩ h(x) = \argmax_{y} \langle w, \Psi(x,y) \rangle h ( x ) = y arg max ⟨ w , Ψ ( x , y )⟩ error type type 1: false positive
type 2: false negative
accuracy: TP + TN TP + TN + FP + FN \frac{\text{TP + TN}}{\text{TP + TN + FP + FN}} TP + TN + FP + FN TP + TN
precision is TP TP + FP ′ \frac{\text{TP}}{\text{TP}+\text{FP}^{'}} TP + FP ′ TP
recall is TP TP + FN \frac{\text{TP}}{\text{TP + FN}} TP + FN TP
example: to assume each class is a Gaussian
discriminant analysis P ( x ∣ y = 1 , μ 0 , μ 1 , β ) = 1 a 0 e − ∥ x − μ 1 ∥ 2 2 P(x \mid y = 1, \mu_0, \mu_1, \beta) = \frac{1}{a_0} e^{-\|x-\mu_1\|^2_2} P ( x ∣ y = 1 , μ 0 , μ 1 , β ) = a 0 1 e − ∥ x − μ 1 ∥ 2 2 maximum likelihood estimate see also
given Θ = { μ 1 , μ 2 , β } \Theta = \{\mu_1, \mu_2, \beta\} Θ = { μ 1 , μ 2 , β }
arg max Θ P ( Z ∣ Θ ) = arg max Θ ∏ i = 1 n P ( x i , y i ∣ Θ ) \begin{aligned}
\argmax_{\Theta} P(Z \mid \Theta) &= \argmax_{\Theta} \prod_{i=1}^{n} P(x^i, y^i \mid \Theta) \\
\end{aligned} Θ arg max P ( Z ∣ Θ ) = Θ arg max i = 1 ∏ n P ( x i , y i ∣ Θ )
How can we predict the label of a new test point?
Or in another words, how can we run inference?
Check P ( y = 0 ∣ X , Θ ) P ( y = 1 ∣ X , Θ ) ≥ 1 \frac{P(y=0 \mid X, \Theta)}{P(y=1 \mid X, \Theta)} \ge 1 P ( y = 1 ∣ X , Θ ) P ( y = 0 ∣ X , Θ ) ≥ 1
Generalization for correlated features
Gaussian for correlated features:
N ( x ∣ μ , Σ ) = 1 ( 2 π ) d / 2 ∣ Σ ∣ 1 / 2 exp ( − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) ) \mathcal{N}(x \mid \mu, \Sigma) = \frac{1}{(2 \pi)^{d/2}|\Sigma|^{1/2}} \exp (-\frac{1}{2}(x-\mu)^T \Sigma^{-1}(x-\mu)) N ( x ∣ μ , Σ ) = ( 2 π ) d /2 ∣Σ ∣ 1/2 1 exp ( − 2 1 ( x − μ ) T Σ − 1 ( x − μ ))
Naive Bayes Classifier
Given the label, the coordinates are statistically independent
P ( x ∣ y = k , Θ ) = π j P ( x j ∣ y = k , Θ ) P(x \mid y = k, \Theta) = \pi_j P(x_j \mid y=k, \Theta) P ( x ∣ y = k , Θ ) = π j P ( x j ∣ y = k , Θ )
idea: comparison between discriminative and generative models
😄 fun fact: actually better for classification instead of regression problems
Assume there is a plane in R d \mathbb{R}^d R d W W W
P ( Y = 1 ∣ x , W ) = ϕ ( W T x ) P ( Y = 0 ∣ x , W ) = 1 − ϕ ( W T x ) ∵ ϕ ( a ) = 1 1 + e − a \begin{aligned}
P(Y = 1 \mid x, W) &= \phi (W^T x) \\
P(Y= 0 \mid x, W) &= 1 - \phi (W^T x) \\[12pt]
&\because \phi (a) = \frac{1}{1+e^{-a}}
\end{aligned} P ( Y = 1 ∣ x , W ) P ( Y = 0 ∣ x , W ) = ϕ ( W T x ) = 1 − ϕ ( W T x ) ∵ ϕ ( a ) = 1 + e − a 1 maximum likelihood 1 − ϕ ( a ) = ϕ ( − a ) 1 - \phi (a) = \phi (-a) 1 − ϕ ( a ) = ϕ ( − a ) W ML = arg max W ∏ P ( x i , y i ∣ W ) = arg max W ∏ P ( x i , y i , W ) P ( W ) = arg max W ∏ P ( y i ∣ x i , W ) P ( x i ) = arg max W [ ∏ P ( x i ) ] [ ∏ P ( y i ∣ x i , W ) ] = arg max W ∑ i = 1 n log ( τ ( y i W T x i ) ) \begin{aligned}
W^{\text{ML}} &= \argmax_{W} \prod P(x^i, y^i \mid W) \\
&= \argmax_{W} \prod \frac{P(x^i, y^i, W)}{P(W)} \\
&= \argmax_{W} \prod P(y^i | x^i, W) P(x^i) \\
&= \argmax_{W} \lbrack \prod P(x^i) \rbrack \lbrack \prod P(y^i \mid x^i, W) \rbrack \\
&= \argmax_{W} \sum_{i=1}^{n} \log (\tau (y^i W^T x^i))
\end{aligned} W ML = W arg max ∏ P ( x i , y i ∣ W ) = W arg max ∏ P ( W ) P ( x i , y i , W ) = W arg max ∏ P ( y i ∣ x i , W ) P ( x i ) = W arg max [ ∏ P ( x i )] [ ∏ P ( y i ∣ x i , W )] = W arg max i = 1 ∑ n log ( τ ( y i W T x i ))
maximize the following:
∑ i = 1 n ( y i log p i + ( 1 − y i ) log ( 1 − p i ) ) \sum_{i=1}^{n} (y^i \log p^i + (1-y^i) \log (1-p^i)) i = 1 ∑ n ( y i log p i + ( 1 − y i ) log ( 1 − p i ))
softmax softmax(y) i = e y i ∑ i e y i \text{softmax(y)}_i = \frac{e^{y_i}}{\sum_{i} e^{y_i}} softmax(y) i = ∑ i e y i e y i where y ∈ R k y \in \mathbb{R}^k y ∈ R k
😄 fun fact: actually better for classification instead of regression problems
Assume there is a plane in R d \mathbb{R}^d R d W W W
P ( Y = 1 ∣ x , W ) = ϕ ( W T x ) P ( Y = 0 ∣ x , W ) = 1 − ϕ ( W T x ) ∵ ϕ ( a ) = 1 1 + e − a \begin{aligned}
P(Y = 1 \mid x, W) &= \phi (W^T x) \\
P(Y= 0 \mid x, W) &= 1 - \phi (W^T x) \\[12pt]
&\because \phi (a) = \frac{1}{1+e^{-a}}
\end{aligned} P ( Y = 1 ∣ x , W ) P ( Y = 0 ∣ x , W ) = ϕ ( W T x ) = 1 − ϕ ( W T x ) ∵ ϕ ( a ) = 1 + e − a 1 maximum likelihood 1 − ϕ ( a ) = ϕ ( − a ) 1 - \phi (a) = \phi (-a) 1 − ϕ ( a ) = ϕ ( − a ) W ML = arg max W ∏ P ( x i , y i ∣ W ) = arg max W ∏ P ( x i , y i , W ) P ( W ) = arg max W ∏ P ( y i ∣ x i , W ) P ( x i ) = arg max W [ ∏ P ( x i ) ] [ ∏ P ( y i ∣ x i , W ) ] = arg max W ∑ i = 1 n log ( τ ( y i W T x i ) ) \begin{aligned}
W^{\text{ML}} &= \argmax_{W} \prod P(x^i, y^i \mid W) \\
&= \argmax_{W} \prod \frac{P(x^i, y^i, W)}{P(W)} \\
&= \argmax_{W} \prod P(y^i | x^i, W) P(x^i) \\
&= \argmax_{W} \lbrack \prod P(x^i) \rbrack \lbrack \prod P(y^i \mid x^i, W) \rbrack \\
&= \argmax_{W} \sum_{i=1}^{n} \log (\tau (y^i W^T x^i))
\end{aligned} W ML = W arg max ∏ P ( x i , y i ∣ W ) = W arg max ∏ P ( W ) P ( x i , y i , W ) = W arg max ∏ P ( y i ∣ x i , W ) P ( x i ) = W arg max [ ∏ P ( x i )] [ ∏ P ( y i ∣ x i , W )] = W arg max i = 1 ∑ n log ( τ ( y i W T x i ))
maximize the following:
∑ i = 1 n ( y i log p i + ( 1 − y i ) log ( 1 − p i ) ) \sum_{i=1}^{n} (y^i \log p^i + (1-y^i) \log (1-p^i)) i = 1 ∑ n ( y i log p i + ( 1 − y i ) log ( 1 − p i ))
softmax softmax(y) i = e y i ∑ i e y i \text{softmax(y)}_i = \frac{e^{y_i}}{\sum_{i} e^{y_i}} softmax(y) i = ∑ i e y i e y i where y ∈ R k y \in \mathbb{R}^k y ∈ R k
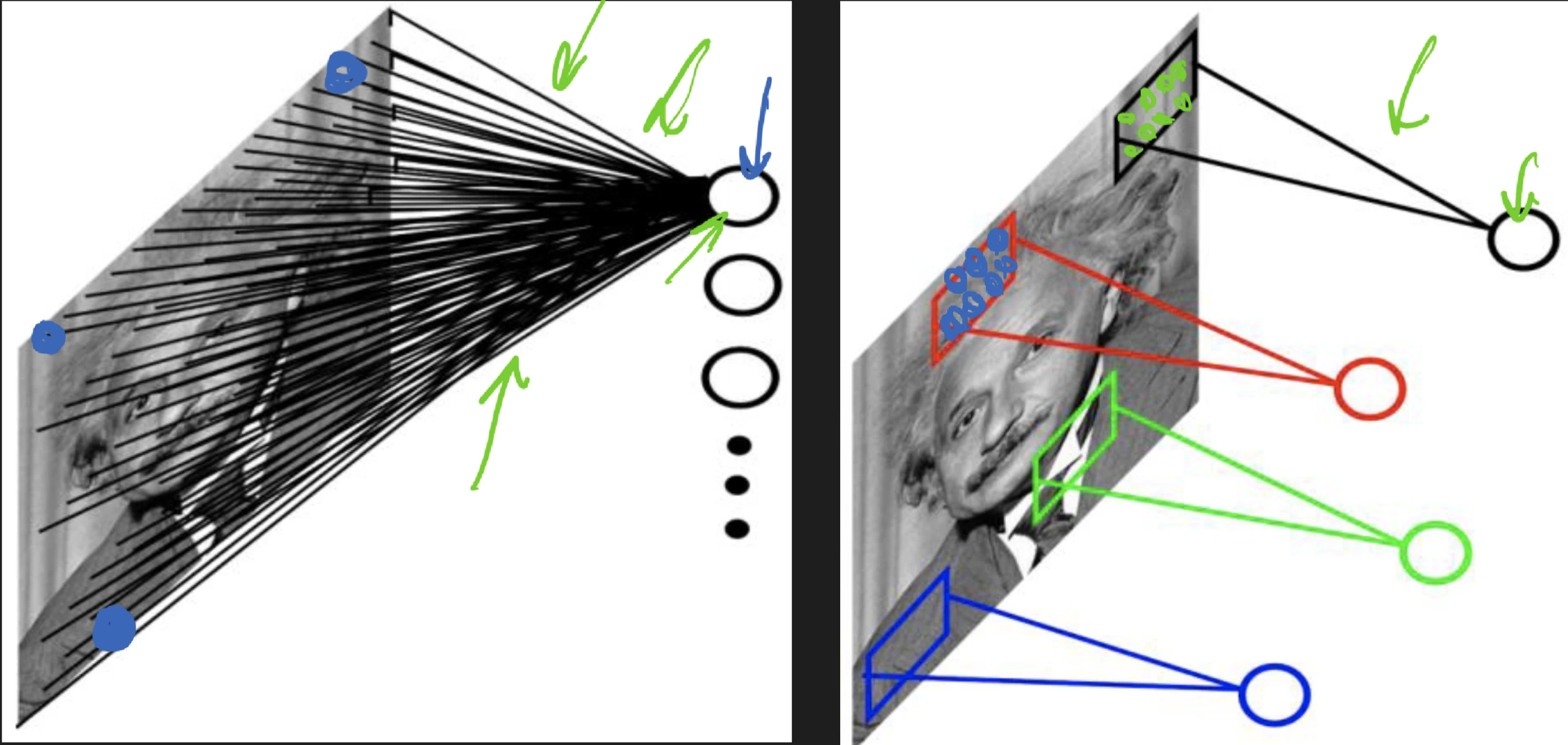
stateless, and usually have no feedback loop.
universal approximation theorem see also (
idea: a single
regression Think of just a linear layers with some activation functions
import torch . optim as optim import torch . nn as nn
class LinearRegression ( nn . Module ): def __init__ ( self , input_dim , output_dim ): super (). __init__ () self . fc = nn . Linear ( input_dim , output_dim ) def forward ( self , x ): return self . fc ( x )
model = LinearRegression ( 224 , 10 ) loss = nn . MSELoss () optimizer = optim . SGD ( model . parameters (), lr = 0.005 )
for ep in range ( 10 ): y_pred = model ( X ) l = loss ( Y , y_pred ) l . backward () optimizer . setp () optimzer . zero_grad () classification Think of one-hot encoding (binary or multiclass) cases
backpropagation context: using
∇ W ( L ( w , b ) ) = ∑ i ∇ W ( l ( f w , b ( x i ) , y i ) ) \nabla_W(L(w,b)) = \sum_{i} \nabla_W (l(f_{w,b}(x^i), y^i)) ∇ W ( L ( w , b )) = i ∑ ∇ W ( l ( f w , b ( x i ) , y i )) This is expensive, given that for deep model this is repetitive!
intuition: we want to minimize the error and optimized the saved weights learned through one forward pass.
vanishing gradient happens in deeper network wrt the partial derivatives
because we applies the chain rule and propagating error signals backward from the output layer through all the hidden layers to
the input, in very deep networks, this involves successive multiplication of gradients from each layer.
thus the saturated neurons σ ′ ( x ) ≈ 0 \sigma^{'}(x) \approx 0 σ ′ ( x ) ≈ 0
solution:
we can probably use activation functions (Leaky ReLU)
better initialisation
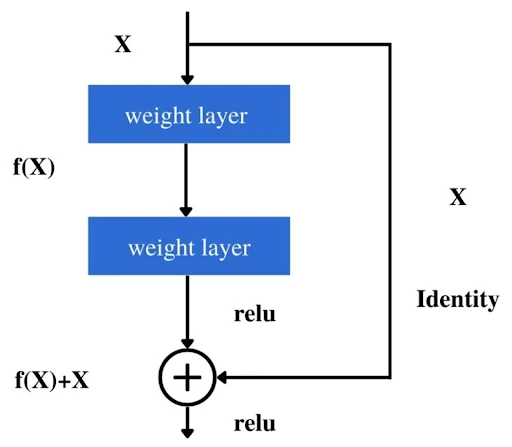
residual network
usually prone to overfitting given they are often over-parameterized
We can usually add regularization terms to the objective functions
Early stopping
Adding noise
structural regularization, via adding dropout
dropout a case of structural regularization
a technique of randomly drop each node with probability p p p
Bibliographie Novikoff, A. B. J. (1962). On Convergence Proofs for Perceptrons. Proceedings of the Symposium on the Mathematical Theory of Automata , 12 , 615–622. Cybenko, G. (1989). Approximation by superpositions of a sigmoidal function. Mathematics of Control, Signals, and Systems , 2 (4), 303–314. usually prone to overfitting given they are often over-parameterized
We can usually add regularization terms to the objective functions
Early stopping
Adding noise
structural regularization, via adding dropout
dropout a case of structural regularization
a technique of randomly drop each node with probability p p p
See also:
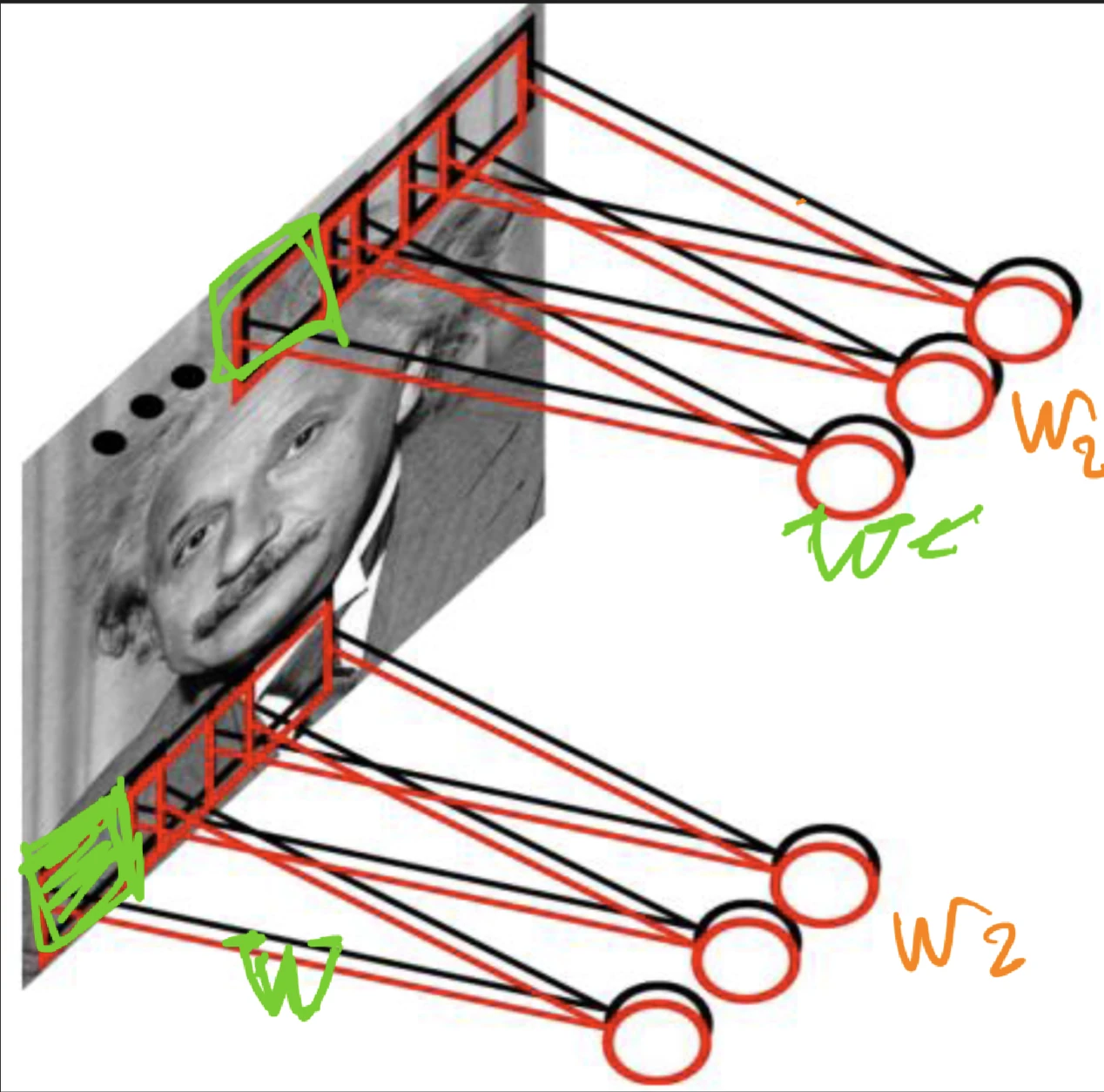
how can we exploit sparsity and locality?
think of sparse connectivity rather than full connectivity
where we exploiting invariance, it might be useful in other parts of the image as well
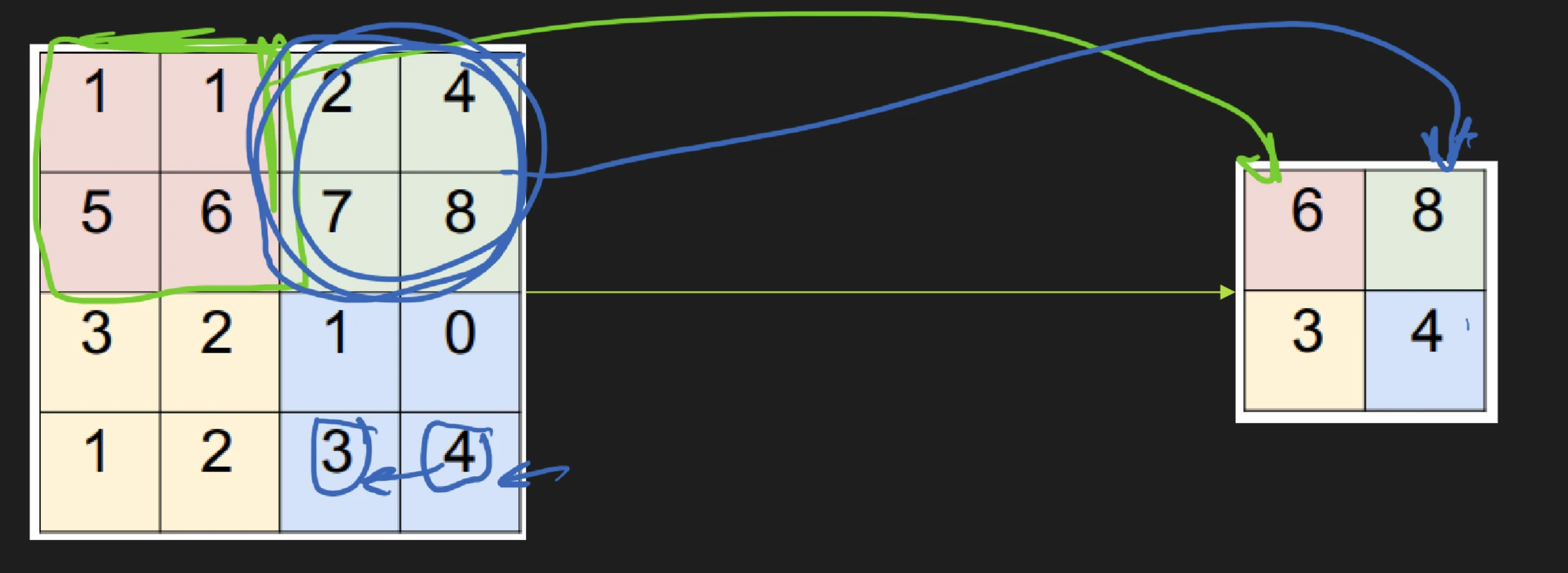
convolution accept volume of size W 1 × H 1 × D 1 W_1 \times H_1 \times D_1 W 1 × H 1 × D 1
filters K K K
spatial extent F F F
stride S S S
amount of zero padding P P P
produces a volume of size W 2 × H 2 × D 2 W_2 \times H_2 \times D_2 W 2 × H 2 × D 2
W 2 = W 1 − F + 2 P S + 1 W_2 = \frac{W_1 - F + 2P}{S} + 1 W 2 = S W 1 − F + 2 P + 1 H 2 = H 1 − F + 2 P S + 1 H_2 = \frac{H_1 - F + 2P}{S} + 1 H 2 = S H 1 − F + 2 P + 1 D 2 = K D_2 = K D 2 = K
1D convolution:
y = ( x ∗ w ) y ( i ) = ∑ t x ( t ) w ( i − t ) \begin{aligned}
y &= (x*w) \\
y(i) &= \sum_{t}x(t)w(i-t)
\end{aligned} y y ( i ) = ( x ∗ w ) = t ∑ x ( t ) w ( i − t ) 2D convolution:
y = ( x ∗ w ) y ( i , j ) = ∑ t 1 ∑ t 2 x ( t 1 , t 2 ) w ( i − t 1 , j − t 2 ) \begin{aligned}
y &= (x*w) \\
y(i,j) &= \sum_{t_1} \sum_{t_2} x(t_1, t_2) w(i-t_1,j-t_2)
\end{aligned} y y ( i , j ) = ( x ∗ w ) = t 1 ∑ t 2 ∑ x ( t 1 , t 2 ) w ( i − t 1 , j − t 2 ) max pooling idea to reduce number of parameters
batchnorm x j = [ x 1 j , … , x d j ] x^{j} = [x_1^j,\ldots,x_d^j] x j = [ x 1 j , … , x d j ] Batch X = [ ( x 1 ) T … ( x b ) T ] T X = [(x^1)^T \ldots (x^b)^T]^T X = [( x 1 ) T … ( x b ) T ] T
Think of using autoencoders to extract
graph TD
A[Input X] --> B[Layer 1]
B --> C[Layer 2]
C --> D[Latent Features Z]
D --> E[Layer 3]
E --> F[Layer 4]
F --> G[Output X']
subgraph Encoder
A --> B --> C
end
subgraph Decoder
E --> F
end
style D fill:#c9a2d8,stroke:#000,stroke-width:2px,color:#fff
style A fill:#98FB98,stroke:#000,stroke-width:2px
style G fill:#F4A460,stroke:#000,stroke-width:2pxsee also
definition Enc Θ 1 : R d → R q Dec Θ 2 : R q → R d ∵ q ≪ d \begin{aligned}
\text{Enc}_{\Theta_1}&: \mathbb{R}^d \to \mathbb{R}^q \\
\text{Dec}_{\Theta_2}&: \mathbb{R}^q \to \mathbb{R}^d \\[12pt]
&\because q \ll d
\end{aligned} Enc Θ 1 Dec Θ 2 : R d → R q : R q → R d ∵ q ≪ d loss function: l ( x ) = ∥ Dec Θ 2 ( Enc Θ 1 ( x ) ) − x ∥ l(x) = \|\text{Dec}_{\Theta_2}(\text{Enc}_{\Theta_1}(x)) - x\| l ( x ) = ∥ Dec Θ 2 ( Enc Θ 1 ( x )) − x ∥
The goal of contrastive representation learning is to learn such an
intuition: to give a positive and negative pairs for optimizing loss function.
training objective we want smaller reconstruction error, or
∥ Dec ( Sampler ( Enc ( x ) ) ) − x ∥ 2 2 \|\text{Dec}(\text{Sampler}(\text{Enc}(x))) - x\|_2^2 ∥ Dec ( Sampler ( Enc ( x ))) − x ∥ 2 2 we want to get the latent space distribution to look something similar to isotopic Gaussian!
denoted as D KL ( P ∥ Q ) D_{\text{KL}}(P \parallel Q) D KL ( P ∥ Q )
The statistical distance between a model probability distribution Q Q Q P P P
D KL ( P ∥ Q ) = ∑ x ∈ X P ( x ) log ( P ( x ) Q ( x ) ) D_{\text{KL}}(P \parallel Q) = \sum_{x \in \mathcal{X}} P(x) \log (\frac{P(x)}{Q(x)}) D KL ( P ∥ Q ) = x ∈ X ∑ P ( x ) log ( Q ( x ) P ( x ) )
Alternative form
KL ( p ∥ q ) = E x ∼ p ( log p ( x ) q ( x ) ) = ∫ x P ( x ) log p ( x ) q ( x ) d x \begin{aligned}
\text{KL}(p \parallel q) &= E_{x \sim p}(\log \frac{p(x)}{q(x)}) \\
&= \int_x P(x) \log \frac{p(x)}{q(x)} dx
\end{aligned} KL ( p ∥ q ) = E x ∼ p ( log q ( x ) p ( x ) ) = ∫ x P ( x ) log q ( x ) p ( x ) d x For relative entropy if ∀ x > 0 , Q ( x ) = 0 ⟹ P ( x ) = 0 \forall x > 0, Q(x) = 0 \implies P(x) = 0 ∀ x > 0 , Q ( x ) = 0 ⟹ P ( x ) = 0 absolute continuity
For distribution P P P Q Q Q
D KL ( P ∥ Q ) = ∫ − ∞ + ∞ p ( x ) log p ( x ) q ( x ) d x D_{\text{KL}}(P \parallel Q) = \int_{-\infty}^{+ \infty} p(x) \log \frac{p(x)}{q(x)} dx D KL ( P ∥ Q ) = ∫ − ∞ + ∞ p ( x ) log q ( x ) p ( x ) d x where p p p q q q P P P Q Q Q
variational autoencoders idea: to add a gaussian sampler after calculating latent space.
objective function:
min ( ∑ x ∥ Dec ( Sampler ( Enc ( x ) ) ) − x ∥ 2 2 + λ ∑ i = 1 q ( − log ( σ i 2 ) + σ i 2 + μ i 2 ) ) \min (\sum_{x} \|\text{Dec}(\text{Sampler}(\text{Enc}(x))) - x\|^2_2 + \lambda \sum_{i=1}^{q}(-\log (\sigma_i^2) + \sigma_i^2 + \mu_i^2)) min ( x ∑ ∥ Dec ( Sampler ( Enc ( x ))) − x ∥ 2 2 + λ i = 1 ∑ q ( − log ( σ i 2 ) + σ i 2 + μ i 2 )) idea: train multiple classifier and then combine them to improve performance.
aggregate their decisions via voting procedure.
Think of boosting, decision tree.
bagging using non-overlapping training subset creates truly independent/diverse classifiers
bagging is essentially bootstrap aggregating where we do random sampling with replacement.
random forests bagging but with random subspace methods
decision tree
handle categorical features
can overfit easily with deeper tree.
boosting a greedier approach for reducing bias where we “pick base classifiers incrementally”.
we will train “weaker learner” and thus it can combined to become “stronger learner”.
note that we can also write a T ϕ a^T \phi a T ϕ ϕ = [ ϕ ( x 1 ) , … , ϕ ( x n ) ] T \phi = [\phi(x^1),\ldots,\phi(x^n)]^T ϕ = [ ϕ ( x 1 ) , … , ϕ ( x n ) ] T
For discrete probability distribution P P P Q Q Q
The idea of training each classifier using a random subset of the feature sets. Also known as feature bagging
fancy name for the measure of size, or the cardinality of the largest sets of points that the algorithm can shatter.
Let H H H C C C
H ∩ C ≔ { h ∩ C ∣ h ∈ H } H \cap C \coloneqq \{h \cap C \mid h \in H\} H ∩ C : = { h ∩ C ∣ h ∈ H } We say that set C C C shattered by H H H H ∩ C H \cap C H ∩ C
∣ H ∩ C ∣ = 2 ∣ C ∣ |H \cap C| = 2^{|C|} ∣ H ∩ C ∣ = 2 ∣ C ∣ Thus, the VC dimension D D D H H H H H H
Note that if arbitrary larget sets can be shattered, then the VC dimension is ∞ \infty ∞
 Lien vers l'original
Lien vers l'original